
Attending Informatica World presents the opportunity to speak with IT professionals about one of the strongest use cases for job scheduling and IT automation: the end-to-end automation of ETL, data warehousing and business intelligence (BI) processes.
In recent years, the democratization of analytic, reporting and BI solutions has become a driving force in the growing complexity of data integration and data warehousing models. Add to the equation the growing complexity and volume of information thanks to Big Data, and it’s no surprise that the underlying ETL and data warehousing processes to integrate and access data from multiple sources is becoming increasingly complex.
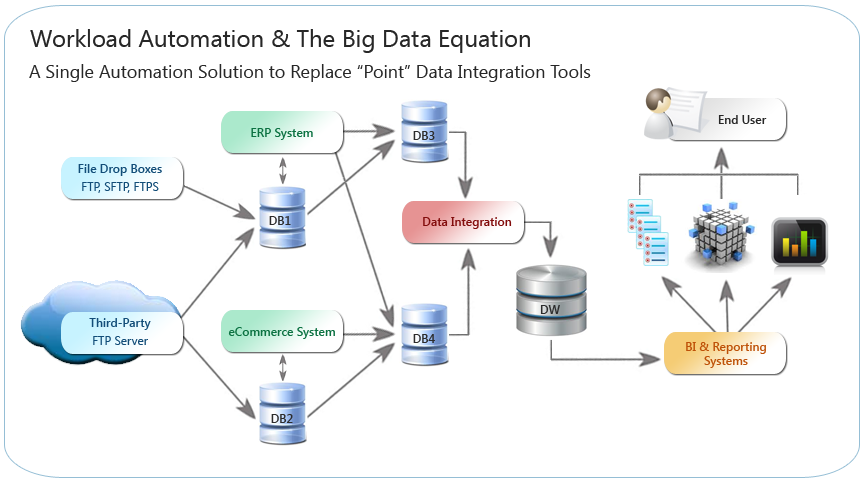
The IT organization is left between a rock and a hard place. On one hand you have the business…the consumers of data…and the concept of “agile BI,” or the ability of IT to more seamlessly and efficiently update data warehousing processes, and thus, subsequent downstream BI and reporting to better meet business demands. On the other hand, the complexity of these underlying data warehousing processes is largely being driven by the increasing numbers of data integration solutions, tools and data sources.
Sessions at last year’s Gartner IT Expo highlighted these issues. According to Gartner, the idea of the single data warehouse model is dead; a federated, heterogeneous collection of data warehouses is the new model and it is forcing IT organizations to streamline the movement of data between multiple repositories in support of real-time analytics. “Data process modeling, mapping and automation will be the key to conquering the challenges associated with Big Data,” said Daryl Plummer at last year’s show.
IT organizations have recognized this and are attempting to automate, but their current approach presents serious limitations. For example, nearly all data warehouse, ETL and BI solutions have native batch scheduling capabilities, but they’re limited in their respective functionality to scheduling on their respective systems. As a result, IT is forced to rely on error-prone and time consuming scripting to pass data and manage dependencies between the various components that comprise the modern data warehousing process.
Unfortunately scripting builds a barrier to garnering the benefits from a concept like “agile BI.” Relying on scripting to manage the extract/warehousing/reporting processes makes it impossible for IT organizations to respond to the requirements of the business, which are increasingly demanding the ability to run reports on-demand or on an inter-day cycle.
Take for example this post I came across from a solutions architect at our partner IBM. It’s a classic example of the sort processes that an IT organization is automating via scripting within a data warehousing environment. In this case, the process includes using Netezza to run an ETL process, upload that data into SAS and run a scoring model. Author Thomas Dinsmore, solutions architect at IBM, sums up the disadvantages of custom coding:
“Custom-coding a scoring model from scratch takes time to design, build, test, validate and tune; customers report cycle times of three to six months to deploy a scoring model into production. Manual coding also introduces a source of error into the process, so that scoring jobs must be exhaustively validated to ensure they produce the same results as the original predictive model.”
This recent article on ZDNet by Dana Gardner, president and principal analyst at Interarbor Solutions, further underscores the issues faced by IT organizations that have adopted an “elemental” approach to automating data integration and data warehousing processes. To use Dana’s words, “data dichotomy” is forcing businesses of all sizes to manage increasing volumes of both internally generated and external sources of data in order to identify new customers and drive new revenue. Yet the use of multiple, “point” data integration solutions creates an “agnostic tool chain” that builds a barrier for IT to deliver that data to the end user via reporting and BI.
The idea behind IT automation is to take an “architectural” approach by unifying those “point” integration solutions into a single framework. The result is ease of authorship, control and upkeep, thereby eliminating “a source of error” that Dinsmore speaks too. IT organizations are able to integrate all data pathways into automated, repeatable processes that deliver control and visibility over all steps of the data warehouse/reporting process by intelligently automating and managing the dependencies, constraints and completion of jobs that exist within these workflows. These steps can include everything from lower-level tasks and data center functions, such as scheduling file transfers, database backups and automating database services such as SSIS or SSRS, to providing production-ready job steps for high-end database appliances and analytic solutions such as Informatica, Netezza, Teradata, DataStage and Cognos, SAP BusinessObjects and more.
And the benefit to the business? It gives them the return on Big Data they’ve been looking for by allowing IT to reduce latency and increase data quality.
Recommended Resource

In recent years, the democratization of analytics and Business Intelligence (BI) solutions has become a driving force in the growing complexity of data integration and data warehousing processes. As a result, the extract, transform and load (ETL) and data integration processes to access and integrate large volumes of data from multiple sources are becoming increasingly intricate. Get the Paper to Learn More